How to solve Kakuro
This web page contains a general description of an method for solving Kakuro puzzles. If the description of the method sounds more puzzling than Kakuro, then you might want to first visit one of the earlier tutorials (here or here).
Unique Partitions
Partitioning a number is to break it up into smaller pieces. If you demand that no two of the partitions are equal, then some partitions are uniquely determined. These are important in Kakuro, because they restricted solutions. The full list of unique partitions upto length five are so important to Kakuro that a case may be made to hold them in one's mind always. Here is the list.
| Parts | Number | Partition |
| 2 | 3 | 1+2 |
| 4 | 1+3 | |
| 16 | 7+9 | |
| 17 | 8+9 | |
| 3 | 6 | 1+2+3 |
| 7 | 1+2+4 | |
| 23 | 6+8+9 | |
| 24 | 7+8+9 | |
| 4 | 10 | 1+2+3+4 |
| 11 | 1+2+3+5 | |
| 29 | 5+7+8+9 | |
| 30 | 6+7+8+9 | |
| 5 | 15 | 1+2+3+4+5 |
| 16 | 1+2+3+4+6 | |
| 34 | 4+6+7+8+9 | |
| 35 | 5+6+7+8+9 | |
| 6 | 21 | 1+2+3+4+5+6 |
| 22 | 1+2+3+4+5+7 | |
| 38 | 3+5+6+7+8+9 | |
| 39 | 4+5+6+7+8+9 | |
| 7 | 28 | 1+2+3+4+5+6+7 |
| 29 | 1+2+3+4+5+6+8 | |
| 41 | 2+4+5+6+7+8+9 | |
| 42 | 3+4+5+6+7+8+9 | |
| 8 | 36 | 1+2+3+4+5+6+7+8 |
| 37 | 1+2+3+4+5+6+7+9 | |
| 38 | 1+2+3+4+5+6+8+9 | |
| 39 | 1+2+3+4+5+7+8+9 | |
| 40 | 1+2+3+4+6+7+8+9 | |
| 41 | 1+2+3+5+6+7+8+9 | |
| 42 | 1+2+4+5+6+7+8+9 | |
| 43 | 1+3+4+5+6+7+8+9 | |
| 44 | 2+3+4+5+6+7+8+9 | |
| 9 | 45 | 1+2+3+4+5+6+7+8+9 |
Algebraic spreadsheet
A spreadsheet contains cells: some of them hold values, the others hold instructions for combining values, ie, formulae. It all sounds like a Kakuro puzzle, and indeed it is. Each white cell will eventually hold a value, and every clue is an instruction that says something like "this, this, and this value add up to so much". The first steps in solving Kakuro are to put a symbol into a cell, and then to see how many other cells can be filled in using the clues and the symbols already in the puzzle. Once you have filled in all the cells that are determined in terms of the symbols and clues, you have to add a new symbol and repeat the process until all the white cells are filled. At the end of it you have a certain number of symbols with unknown values which you must find. The gain is that the number of unknowns is smaller than the number of white cells.
Deep Geek zone: why the spreadsheet works
If you are a geek you may want to read this para and the next. Kakuro is a problem in linear algebra. There are variables: one to each cell, and a set of linear equations, stating that certain of these values sum up to the clues. Let A be the matrix that maps the variables x into the clues c: call this the template matrix, since it depends only on the template and not the values of the clues. Since the number of clues is usually less than the number of variables, the matrix A is a rectangular matrix. It has a kernel, ie, has solutions with . The dimension of the null space of is the number of linearly independent non-zero solutions of , ie, the number of free variables. Call this . The spreadsheet technique always results in a number of unknowns greater than or equal to the dimension of the null space. Call this number . If , then one quickly finds equations for variables, leaving variables to be solved through inequalities.
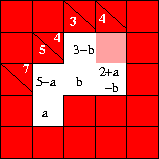
Take the simple example
which we solved earlier by putting a variable called in the
cell Bd. Instead we could start by putting a variable
in Db. Then we would need a second variable when we spreadsheet into the
cell Cc. This would allow us to fill up everything uniquely until we
get to the pink coloured cell Bd. In this cell we would get one value
if we fill according to the row, and another if we fill according to the
column. Since the value in the cell must be unique, we must equate the two.
This gives the equation
ie,
Excess variables will always be eliminated in this way during the spreadsheet
part of the method.
Self-contained blocks
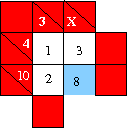
After all the free variables are identified, check whether there are simple sub-problems which can be eliminated. These are called self-contained blocks. Self contained blocks are blocks of cells which make up a sub-puzzle which can be solved without looking at the rest of the puzzle. An example of a self-contained block is a 2×2 set of cells in which 3 clues ask for partitions into two. An example is the trick on the left. In this especially simple case, the self-contained block comes with two interlocking clues which can be solved by unique partitions. Puzzle setters should note that the clue value has to be larger than 11. Puzzle solvers should note that the part of the puzzle outside the self contained block behaves as if it is replaced by a single clue in the cell marked blue with value .
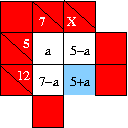
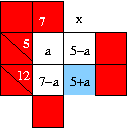
Practical application of the idea of self-contained blocks is more likely to be like the examples shown here. The spreadsheet stage of the method would give a result as shown. As far as the rest of the puzzle is concerned, this part of the puzzle could be replaced by a clue inside the box in blue. However, the block cannot be completely solved without solving the remainder of the puzzle. As it stands, all the Type 1 constraints can be used to show that
Some self-contained blocks could be large and irregular in shape. The one trusty way of finding them is to step through the spreadsheet procedure and then find whether some variable, or a group of variables, is geographically localized. Any such set is part of a self-contained block. A rule of the thumb is to look for parts of the puzzle which communicate with the remainder only through a single row or column. The two examples on the right communicate through a single column.
Divide and conquer: eliminating blocks
No matter what the shape of a self-contained block is, as far as the rest of the puzzle is concerned, it reduces to a single filled white cell. We have called it a phagocyte because it eats up the block. The phagocyte shows the rest of the puzzle a single number. If the number is part of a column then it is the sum of all the row clues in the block minus the sum of all the other column clues inside the block. If it is part of a row then it is the sum of all the column clues minus the sum of all other row clues inside the block. As simple as that: the self-contained block has been eliminated from the puzzle.
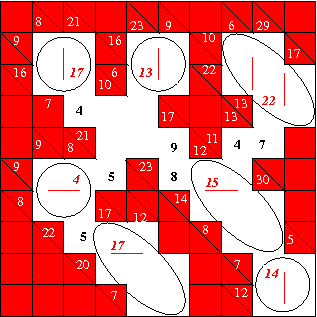
As you can see, this leads to a divide and conquer strategy: use the spreadsheet method to break up the puzzle into self-contained blocks. As soon as you find a block, it can be replaced by a number computed just from the clues. Once you have broken the puzzle into independent pieces, solve each by piece by application of the rules. A few remaining ambiguities are solved when glueing everything back together. Whenever the effort in solving a puzzle grows faster than linearly in the number of pieces, it is faster to create a divide and conquer strategy.
Here is an example of a puzzle which can be almost entirely separated into small self-contained blocks, and then replaced by phagocytes which bear the numbers shows in red italics. That enables us to fill in the cell values in black, leaving only a 2×2 block to be solved. You can begin to recognize the tell-tale geometric shape of a self-contained block. It communicates with other parts of the puzzle only through a single row or column. In the example here, that row or column is indicated by the red lines inside the ellipses. The phagocyte at the top right exhibits , in accordance with the rule. The one directly below that exhibits , where the column sum inside the block is modified by the forced 5 which is outside the block but inside the column. The phagocyte marked 15 also needs this twist in the count. Finally check that the empty 2×2 block which the puzzle has been reduced to cannot be uniquely solved without expanding the phagocyte with label 13. This is one of the ambiguities which are resolved when gluing the puzzle back together. By using a divide and conquer strategy, this 48 piece puzzle has been converted into 5 puzzles of 4 pieces each and 3 puzzles of 7 pieces each. One of the 4 piece puzzles depends on the solution of another 4 piece puzzle. Nevertheless, the sum of the parts is much easier than the whole.
The two rules are inequalities
Once one has solved the clues, examined and isolated all the self-contained blocks, one is still left with the last step of the solution: putting unique values to the free variables. The number of free variables is equal to the null space of the puzzle. At this stage, the clues have yielded up all their information and are no longer of use. To find an unique solution in the null space we have to impose the rules of the game. There are two rules—
- Use only the digits 1 to 9. This rule gives inequalities of the form , where is the value of any cell. We call these Type 1 inequalities. If we are lucky, then several Type 1 inequalities will lead to an unique result. But usually this does not happen.
- No digit is repeated in solving a clue. This rule translates to inequalities of the kind . We call these Type 2 inequalities. These rule out individual values for one variable or lines for multiple variables.
Is Kakuro in NP?
An integer programming problem is an optimization problem of the form
where and are given
functions.
The Kakuro problem can be mapped into this in the following
way. The number of variables, , is the dimension of the
null space of the linear algebra problem. Since there are
white cells in the problem, then there are Type 1
constraints. These can be written in the form of linear
constraints in the standard form . The
constraints become where is
a matrix, which is possibly reducible,
since some of the constraints could be identical. The
cost function can be created from the Type 2 inequalities
,
by squaring the difference
,
and summing the squares over all constraints.
Since no clue in Kakuro
can involve partitions into more than 9 pieces therefore the number of
Type 2 constraints must be between and .
The number can reduce if some of the constraints are identical or are
obviously satisfied by integers. We have , where is a number linear in .
The Kakuro problem is the non-linear integer programming problem
.
Since the constraints are linear, they make up the faces of a polyhedron in the dimensional space. The integer programming problem can be solved, in principle, by visiting every integer point inside this polyhedron and computing the cost function there. The general integer programming problem is known to be NP-hard. In other words, one can check a claimed solution for variables, in a number of steps of arithmetic which is less than some fixed power of . However, generating such a solution takes an amount of arithmetic larger than any fixed power of .
Is Kakuro in NP? The spreadsheet part of the algorithm takes time of order and gives free variables. The integer programming problem in these variables can be solved by enumeration in at most steps, since each variable can take at most 9 values; this certainly grows faster than any fixed power of . On the other hand, if one were given a claimed solution, one could check it by filling this back into the spreadsheet in a time of order M. Since is not exponentially smaller than , an exponential in cannot be polynomial in . This shows that if enumeration were the only way of solving Kakuro puzzles, then generating a solution of Kakuro would take non-polynomially large time. In this case Kakuro would be in NP.
One can carefully define subclasses of NP complete problems which could be in P. One example is the travelling salesman problem on a circle: ie, a graph in which every node is joined to exactly two others. Is the most general Kakuro in such a easily solvable subclass of integer programming problems? The answer is no, Kakuro is in NP. If you want to write a sleek general purpose Kakuro solving program, you had better incorporate a fast algorithm for solving integer programming problems.
Even if Kakuro turns out to be in NP, all puzzles need not be hard to solve. If a puzzle turns out to be entirely decomposable into small self-contained blocks (such as the large example above), then such a puzzle would clearly be simple— perhaps even too simple to give us much pleasure in solving it. A satisfactory puzzle is one which lies on the borderline of solvability: it looks like a prime candidate for lengthy and frustrating work, but then turns out to contain a key simplification which reduces the problem to something simpler. It is not known whether providing a good mathematical definition of a satisfactory problem is in NP.
© Sourendu Gupta. Mail me if you want to reproduce any part of this page. My mailing address is a simple (satisfactory) puzzle for you to solve. Created on 23 November, 2006. Last modified on Apr 27, 2009.